Surveillance capitalism bedtime stories…
…if you don’t want to get much sleep. Although the privacy issues are paramount, another problem with companies compiling vast amounts of information about us is that we don’t know what they know.
By Brad Berens
Companies spying on Americans for our entertainment and their profit is nothing new.
How else can we understand Candid Camera, the show that for nearly 70 years put people in embarrassing situations, filmed those situations, and then broadcast the footage on TV?
One of the most popular things I’ve ever written online was a single sentence piece called “You Are Where You Live.” It featured a link to a site where you could enter your zip code and get the disturbingly accurate Claritas/Prizm profile for your neighborhood. This was when I was the digital editor at EarthLink, the ISP, and ran a weekly newsletter called eLink.
“My TiVo Thinks I’m Gay.” Back in the early 2000s, a story circulated about a straight guy who liked a show that straight guys don’t typically like. His TiVo (remember TiVo?) concluded that he was gay and started recording gay-themed programming. The guy then started recording more straight-seeming content (sports, military history) in an effort to change the TiVo’s mind. This became a plot in a couple of sitcoms. (Here’s a WSJ summary from 2002.)
Relatedly, for years the Amazon algorithm must have thought that I suffer from Sybil-like dissociative identity disorder because my entire family uses the same Amazon Prime account, which is under my name. This also used to be the case with Netflix, but now the streaming service has profiles for different users.
Whether it’s dancing on TikTok, posing for a selfie on Instagram, arguing politics on Twitter, reconfiguring your resume on LinkedIn, or trying to convince folks that you’re living your best life on Facebook, people curate how they present themselves on social media. Other humans on the social media platform judge you based on your curation. Meanwhile, algorithms render different judgments based on exponentially more information. Google collects much more information about us, but because we’re not curating ourselves when we search for things, it doesn’t bother us. It should.
In 2012, Charles Duhigg reported a New York Times story about how an angry father confronted the manager of his local Target because his teen daughter had started receiving coupons for a first-trimester pregnancy. It turned out that the daughter really was pregnant but hadn’t shared the news with Dad. Target had data scientists tracking purchases (like unscented skin lotion) closely associated with early pregnancy and then sending coupons. What’s unsettling is that Target didn’t stop doing this sort of thing after the incident: instead, the retailer started hiding pregnancy-related coupons inside a “nothing to see here” mass of other coupons.
For an eye-popping, uh-oh-inducing, account of just how much companies infer about you based on what you type into a search bar, read Seth Stephens-Davidowitz’s book Everybody Lies: Big Data, New Data, and What the Internet Can Tell Us About Who We Really Are.
While there are obvious and urgent privacy issues with these stories, I also think that they are troubling because of the information asymmetries between the corporations and the individuals. “Information Asymmetries” is fancy talk for spying and not sharing that you know a lot about somebody with that somebody.
This is not always a technology story. Many years ago, I saw a documentary about how cults recruit new members on college campuses. One of the former members shared that when a new recruit was targeted, the cult members would invite that target to a party where the recruit was the only person who was not already a member of the cult. Everybody in the room was working towards the same goal of charming the target into joining the cult, but the target had no idea this was happening. (If anybody can help me find this documentary, I’d be grateful.)
It gets worse with social media.
A few columns back, I argued that “Facebook is Creepier than Google” because Facebook behaves like somebody who eavesdrops on your conversation at a party and then tries to sell you something based on what you said to other people.
One thing I missed is that this is a party where you’re working to make an impression. Then, rather than selling you something based on your designer outfit, your acerbic banter, or the nice bottle of wine you brought to the host, the eavesdropping seller goes through your online activity to see that you bought the wine at Costco, you stole a witty line from a meme, and your outfit is a knockoff.
Whether it’s dancing on TikTok, posing for a selfie on Instagram, arguing politics on Twitter, reconfiguring your resume on LinkedIn, or trying to convince folks that you’re living your best life on Facebook, people curate how they present themselves on social media. Other humans on the social media platform judge you based on your curation. Meanwhile, algorithms render different judgments based on exponentially more information.
You don’t wear a fancy outfit to the library. Google collects much more information about us, but because we’re not curating ourselves when we search for things, it doesn’t bother us. It should.
Can anything be done?
Yes. We can demand that digital platforms like Facebook and Google transparently share with us the logic by which they show us things, whether those things are professionally-created content, user-generated content, or ads.
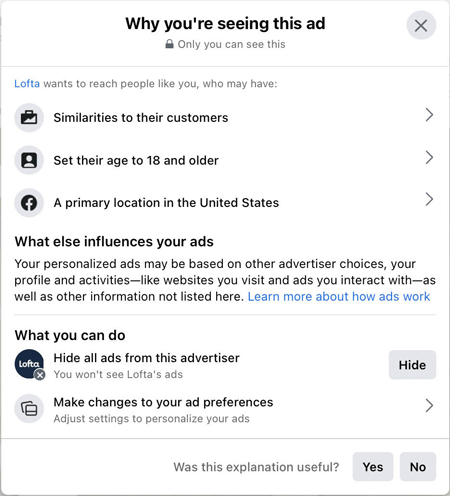 Meta (Facebook and Instagram) has an inadequate “Why am I seeing this ad?” option (right) that effectively says nothing beyond, “because we’re tracking everything you do.”
Meta (Facebook and Instagram) has an inadequate “Why am I seeing this ad?” option (right) that effectively says nothing beyond, “because we’re tracking everything you do.”
Note, please, that the “What you can do” invitation looks like you’re helping yourself when you’re actually giving Meta even more information about you so that they can more effectively target you.
What I want to know is precisely why I am seeing something when I see it. What about my click-stream informed this? And, if I don’t like the logic, I’d like to be able to delete the data that led to that logic.
Social media and search companies will fight hard against this. They will claim that they don’t know why the algorithms serve up particular items (which is scary in different ways), and that even if they could share the data it would overwhelm users.
Don’t believe them.
Instead, get ready to vote in November and then again in November of 2024. Only the Federal government can make this happen.
The Biden administration is working, albeit slowly, to make the internet safer for citizens than it is for corporations, particularly Lina Khan and Tim Wu. Getting there will take time, so let’s give them that time.
__________

Brad Berens is the Center’s strategic advisor and a senior research fellow. He is principal at Big Digital Idea Consulting. You can learn more about Brad at www.bradberens.com, follow him on Twitter, and subscribe to his weekly newsletter (only some of his columns are syndicated here).
See all columns from the Center.
September 7, 2022